Machine Learning Classification Algorithms: Decision Trees
本文最后更新于:1 年前
Introduction
(PS:本文内容是学习高级树模型(GBDT,XGBoost)的基础,强烈建议在看那些内容之前先了解本文的内容!)
本文主要是介绍常用的三种决策树模型:ID3、C4.5和CART。决策树(Decision Tree)是一种有监督分类模型(稍加改造可进行回归任务)。
比如我们要判断一个瓜是不是好瓜,对于人来说,要判断一个瓜是不是好瓜,可能会先去看看色泽,然后看看根蒂,然后再敲一敲听听声音,这样经过一系列的决策过程。
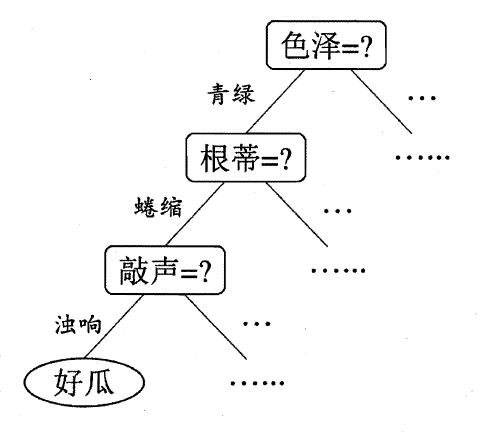
决策树正是模拟了这样的过程。给定数据集,决策树会不断地选择最佳的特征将数据集进行切分(如选择色泽,然后将数据分为青绿、乌黑、浅白这几个子集),然后递归地进行下去,直到达到停止条件:
- 每个叶子节点的样本都属于同一个类别
- 没有可供划分的特征,或者集合中每个样本所有特征取值都相同
- 决策树达到预先指定的最大深度
所以决策树算法要解决的关键问题就是如何去选择当前最好的划分特征。
ID3
ID3算法根据信息熵来进行特征的划分。信息熵是衡量一个随机变量信息量的度量,如果把数据集的标签\(y\)看作是随机变量,那么\(y\)的熵越小代表不确定性越小(集合里几乎都是一种类别的样本),熵越大代表不确定性越大(集合包含不同类别的样本),其公式为: \[ Ent(D)=-\sum_{k=1}^{|\mathcal Y|}p_k\log p_k \] \(Ent(D)\)代表集合\(D\)对应的熵,\(|\mathcal Y|\)是类别数量,二分类就是\(|\mathcal Y|=2\),\(p_k\)为第\(k\)个类别对应的概率(频率)。很自然的,我们可以根据划分前后熵的变化来确定划分特征的选择,如果划分之后熵减小的最多,那么这个特征也是最好的。假设我们选定特征\(a\)来对集合进行划分,特征\(a\)共有\(V\)个离散取值,那么划分之后将会产生\(V\)个子集,我们记每个子集为\(D^v, v=1,\cdots, V\)。那么,信息增益可以写为: \[ Gain(D,a)=Ent(D)-\sum_{v=1}^V \frac{|D^v|}{|D|}Ent(D^v) \] 不过,ID3存在两个致命的缺点:
- 无法对连续取值的特征进行计算
- 对取值较多的特征具有很大的偏向性(极端的情况,把样本编号作为特征,由于每个样本的编号都不同,分裂之后每个自己只有一个样本/类别,熵是最小的)
C4.5
C4.5算法在ID3的基础上做了诸多改进。C4.5解决了ID3对于取值数目较多的特征的偏向性问题,其采用的方案很直观,即对信息增益除以一个系数,特征取值数目越多的特征系数越大,该划分标准被称作是信息增益率: \[ Gain\_ratio(D,a)=\frac{Gain(D,a)}{IV(a)} \] 其中\(IV(a)=-\sum_{v=1}^V\frac{|D^v|}{|D|}\log \frac{|D^v|}{|D|}\)。其实\(IV(a)\)可以看作是“划分之后每个样本属于集合\(v\)的概率”这个随机变量的熵,划分的子集越多,划分之后属于哪个集合就越不确定,所以熵就越大。
不过信息增益率反而会对特征取值数目少的特征有所偏好,所以C4.5算法是先计算信息增益,确定信息增益高于平均值的候选集,再从中选择信息增益率最高的特征。
除此之外,C4.5还能处理连续取值的特征,其做法是“离散化”,即将连续取值划分为若干个离散的区间,一般二分比较常用。设连续特征\(a\),假设其出现了\(n\)个取值,将其排序得到\(\{a^1,a^2,\cdots,a^n\}\),我们考虑每两个相邻节点的中点集合\(T_a=\{\frac{a^i+a^{i+1}}{2}|1\leq i \leq n-1\}\),之后我们就可以像考察离散属性值一样选择最优划分。
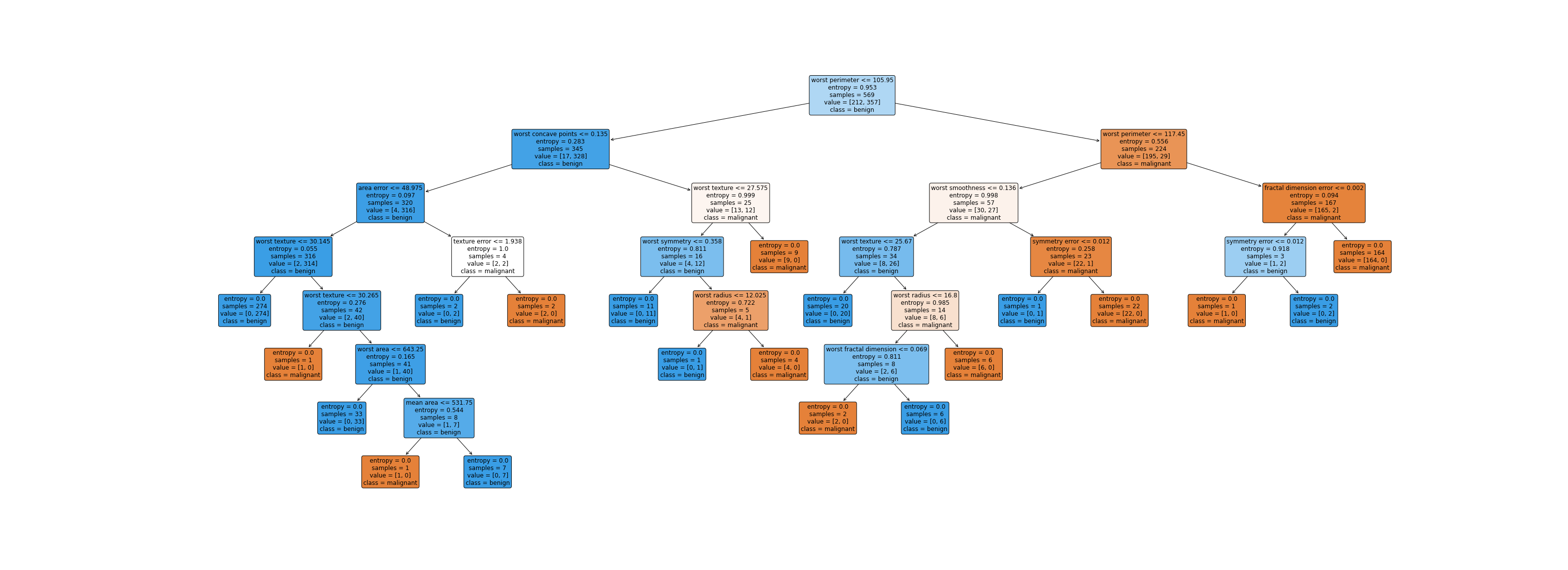
下图是在breast cancer数据上决策树的可视化(图片太大了,可以点开放大🔍看):
CART
CART (Classification and Regression Trees) 是一种应用广泛的决策树模型,既可应用于分类任务也可应用于回归任务。
CART Regression
我们先来说说CART怎么进行回归。在回归问题中,CART使用了MSE作为划分准则: \[ \frac{1}{N}\sum_{i=1}^N (f(x_i)-y_i)^2 \] 如果CART有\(M\)片叶子,那么相当于CART将输入划分成了\(M\)个单元\(R_m, m=1,\cdots,M\),也即有\(M\)个输出,那么该CART在数据集上的MSE为: \[ \frac{1}{N}\sum_{m=1}^M\sum_{x_i\in R_m} (c_m-y_i)^2 \] 这里\(c_j\)为叶子节点\(j\)的输出,一般选为对应样本的均值\(c_m=\text{avg}(y_i|x_i\in R_m)\)。这样,剩下的问题就是如何确定每次的切分特征和切分点了。假设选择的特征是\(j\),切分点\(s\),那么该划分方案对应的损失为: \[ \min_{c_1}\sum_{x_i\in R_1\{j,s\}}(y_i-c_1)^2+\min_{c_2}\sum_{x_i\in R_2\{j,s\}}(y_i-c_2)^2 \] 遍历所有的\(j\)和\(s\),我们就能找到最佳的特征和切分点: \[ \min_{j,s}\left[\min_{c_1}\sum_{x_i\in R_1\{j,s\}}(y_i-c_1)^2+\min_{c_2}\sum_{x_i\in R_2\{j,s\}}(y_i-c_2)^2\right] \]
算法流程大致如下:
CART Decision Tree Algorithm
INPUT: 数据集 \(D=\{(x_1,y_1),\cdots,(x_N,y_N)\}\)
OUTPUT: 预测值\(\{\hat y_1,\cdots,\hat y_N\}\)
PROCEDURE:
1. 选取当前最优切分特征变量\(j^*\)与最优切分点\(s^*\)
设当前选择的切分变量为\(j\),切分点为\(s\)那么可以根据切分点将数据集分为两个子集,一个是\(R_1(j,s)=\left\{x|x^{(j)}\leq s\right\}\),另一个是\(R_2(j,s)=\left\{x|x^{(j)}> s\right\}\)。 遍历所有的\(j\),求解 \[ \min_{j,s}\left[\min_{c_1}\sum\limits_{x_i\in R_1(j,s)}(y_i-c_1)^2+\min\limits_{c_2}\sum\limits_{x_i\in R_2(j,s)}(y_i-c_2)^2\right] \] 注意\(\hat c_1=\frac{1}{N_1}\sum\limits_{x_i\in R_1(j,s)}y_i\) 2. 用选定的\((j^*,s^*)\)来划分区域并计算输出值
此时,我们还需要确定这两个区域(划分到同一个区域的样本对应的输出是相同的)的输出值\(c_1\)和\(c_2\),其确定方式是使得对应区域上的均方误差最小。这样我们相当于得到了给定\(j,s\)下的损失,所以只要找出使得损失最小的\(j^*,s^*\)即可:
3. 递归地对划分出来的两个区域重复步骤1和步骤2,直到满足停止条件
4. 最后将输入空间划分为\(M\),输出\(f(x)=\sum_{m=1}^M \hat c_m I(x\in R_m)\)
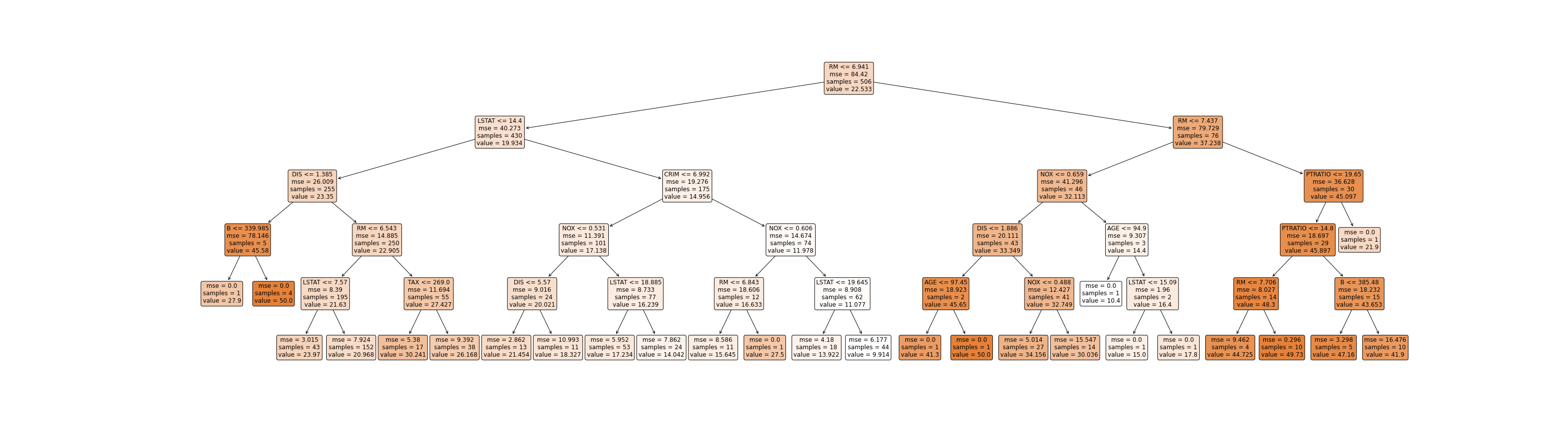
下图是在波士顿房价数据上决策树的可视化(图片太大了,可以点开放大🔍看):
CART Classification
从前面的讨论可以看到,CART回归树是一棵二叉树,对于分类任务,CART也是一棵二叉树。我们先来介绍CART的划分准则,再来介绍它是怎么进行划分的。
采用基尼系数作为准则,基尼系数的计算依赖于基尼值: \[ \begin{align} Gini(D)&=1-\sum_{k=1}^{|\mathcal Y|}p_k^2 \end{align} \] 直观上来说,基尼值表示随机抽取两个样本,其类别不一致的概率
如果说一个特征越好,那么划分之后其每个子集对应的基尼值应该越小越好。基尼系数的定义为: \[ Gini\_index(D,a)=\sum_{v=1}^V \frac{|D^v|}{|D|}Gini(D^v) \]
对于离散取值特征,CART不会根据不同取值个数进行划分,而是和连续值类似,会确定一个“划分点”,将样本进行二分。比如对于特征\(a\),其对应取值为\(\{a^1,a^2,\cdots,a^n\}\),CART会考察每个取值,将样本集划分为特征\(a\)是不是等于\(a^i\)两部分,然后计算基尼系数,最终会采用基尼系数最小的取值作为划分点。
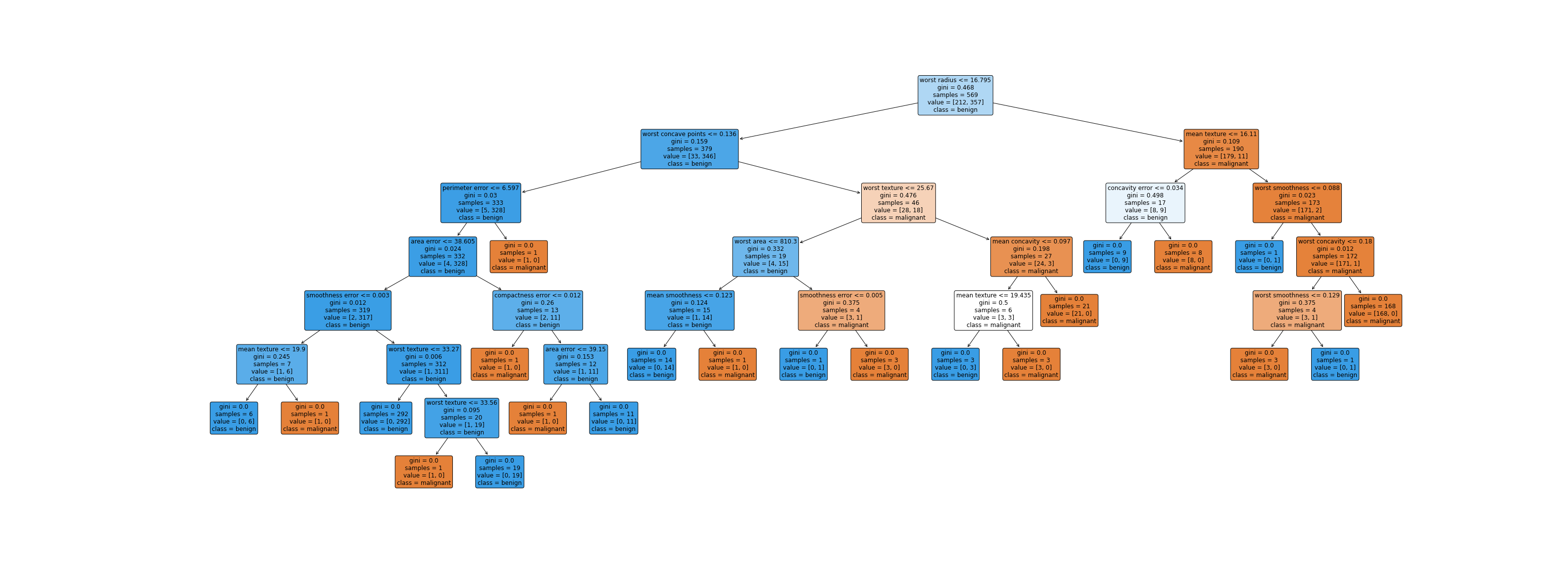
下图是在breast cancer数据上决策树的可视化(图片太大了,可以点开放大🔍看):
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!