Generative Probabilistic Novelty Detection with Adversarial Autoencoders
本文最后更新于:2 年前
Introduction
这篇文章介绍了一种基于概率分布的异常检测方法。其基本思想是假设正常样本服从定义在流形\(M\)上的分布,而对于任意一点\(\bar x\),通过投影到流形\(M\)上\(x^\parallel\),可以分解为平行于切空间的部分\(x^\parallel\)和正交与切空间的部分\(x^\bot\)。原始的坐标\(\bar x\)被转换到\(x^\parallel\)局部坐标系中,然后似然通过转换后的坐标系进行计算。
Methodology
Generative Probabilistic Novelty Detection
我们假设训练数据\(x_1,\cdots,x_N\),其中\(x_i\in\mathbb{R}^m\),从一个分布采样的来,并带有随机噪声\(\xi\): \[ x_i=f(z_i)+\xi_i, \space\space\space i=1,\cdots,N \] 其中\(z_i\in\mathbb{R}^n\),\(f:\Omega\mapsto\mathbb{R}^m\)定义了一个\(n\)维带参流形\(\mathcal{M}\equiv f(\Omega)\)。注意这里噪声的加入使得样本的值域扩展到了整个实数空间。同时假设存在\(g:\mathbb{R}^m\mapsto\mathbb{R}^n\),对任意\(x\in\mathcal{M}\)都有\(f(g(x))=x\)。\(f\)和\(g\)后面会通过神经网络实现。
对于一个测试样本\(\bar{x}\in\mathbb{R}^m\),我们可以得到其在\(M\)上的投影,这是通过逆变换\(\bar z = g(\bar x)\)得到对应\(z\)的然后再通过\(\bar x^{\parallel}=f(\bar z)\)得到。\(f\)在\(\bar z\)的一阶泰勒展开为: \[
f(z)=f(\bar z)+J_f(\bar z)(z-\bar z)+O(\parallel z-\bar z\parallel ^2)
\] 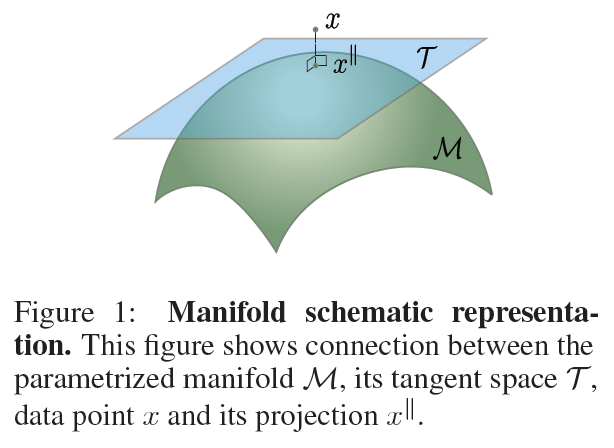
其中\(J_f(\bar z)\)为\(f\)在点\(\bar z\)的雅各比矩阵。\(\mathcal T=\text{span}(J_f(\bar z))\)代表点\(\bar z\)处由\(J_f(\bar z)\)的\(n\)个独立向量组成的切空间。通过对\(J_f(\bar z)\)进行奇异值分解\(J_f(\bar z)=U^\parallel SV^\top\)。 \[ \bar w=U^\top\bar x=\left[\begin{matrix}U^{\parallel^\top}\bar x\\ U^{\bot^\top}\bar x\end{matrix}\right]=\left[\begin{matrix}\bar w^\parallel\\ \bar w^\bot\end{matrix}\right] \] 坐标\(\bar w\)可以分解为平行于\(\mathcal T\)和正交于\(\mathcal T\)两部分。
定义在施加变换前后的坐标系上的概率分布\(p_X(x)\)和\(p_W(w)\)是等价的,不过对于\(p_W(w)\),我们假设平行部分和正交部分是独立的,即: \[ p_X(x)=p_W(w)=p_W(w^\parallel,w^\bot)=p_{W^\parallel}(w^\parallel)p_{W^\bot}(w^\bot) \] 这一假设的依据是随机噪声部分假设主要是往流形之外偏离的,即与\(\mathcal T\)正交,所以\(W^\bot\)主要是反映噪声的部分。而噪声与样本分布相独立的假设是合理的。于是,异常分数可以定义为: \[ p_X(\bar x)=p_{W^\parallel}(\bar w^\parallel)p_{W^\bot}(\bar w^\bot)=\begin{cases}\geq \gamma \Rightarrow \text{Inlier}\\<\gamma\Rightarrow\text{Outlier}\end{cases} \]
Computing the Distribution of Data Samples
上面的异常分数需要计算\(p_{W^\parallel}(\bar w^\parallel)\)和\(p_{W^\bot}(\bar w^\bot)\)。给定测试样本\(\bar x\),投影到流形\(\bar x^\parallel=f(g(\bar x))\)。\(\bar w^\parallel\)可以重写为\(\bar w^\parallel=U^{\parallel^\top}\bar x=U^{\parallel^\top}(\bar x-\bar x^{\parallel})+U^{\parallel^\top}\bar x^\parallel=U^{\parallel^\top}\bar x^\parallel\),即我们假设\(U^{\parallel^\top}(\bar x-\bar x^\parallel)\approx 0\)。于是有\(w^\parallel(z)=U^{\parallel^\top}f(\bar z)+SV^\top(z-\bar z)+O(\parallel z-\bar z\parallel^2)\)。
如果\(Z\)为定义在流形上的概率分布,那么: \[ p_{W^\parallel}(w^\parallel)=|\text{det}S^{-1}|p_Z(z) \] \(p_{W^\bot}(w^\bot)\)由半径为\(\parallel w^\bot\parallel\)的超球体\(\mathcal S^{m-n-1}\)来进行估计: \[ p_{W^\bot}(w^\bot)\approx\frac{\Gamma(\frac{m-n}{2})}{2\pi^{\frac{m-n}{2}}\parallel w^\bot\parallel^{m-n}}p_{\parallel W^\bot\parallel}(\parallel w^\bot\parallel) \]
其中\(\Gamma(\cdot)\)代表Gamma函数。
Manifold Learning with Adversarial Autoencoders
为了学习映射\(f\)和\(g\),我们使用了AAE框架,如下图所示:
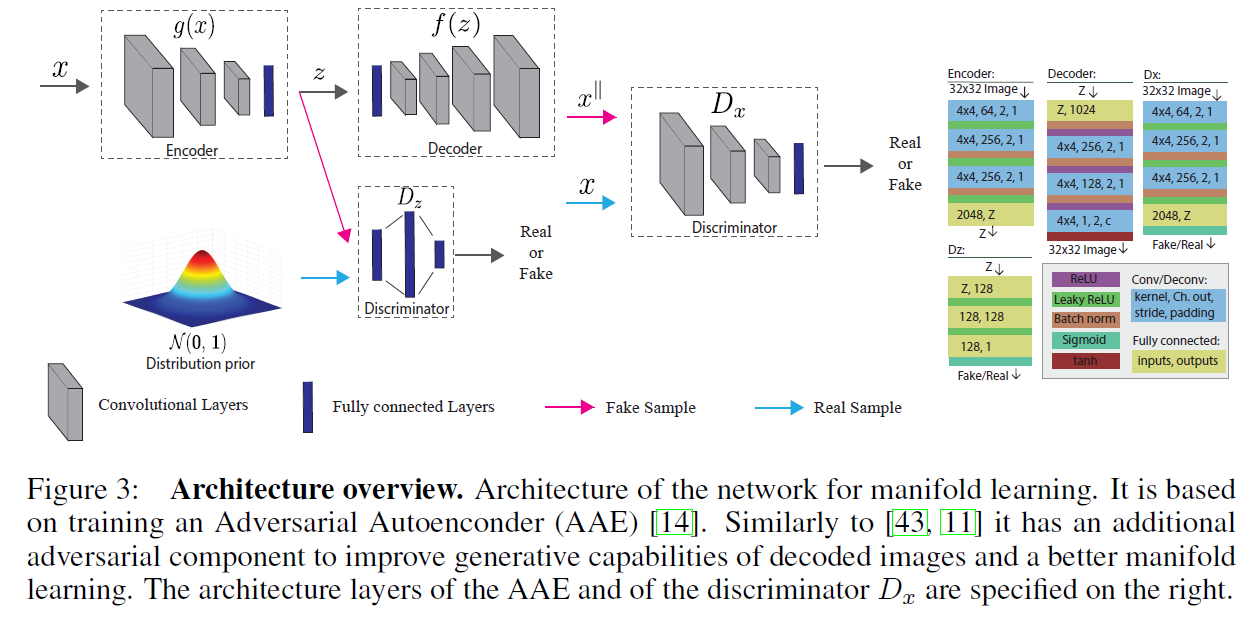
除了常规的AAE外,我们还为\(x\)添加了一个额外的判别器。
Adversarial Losses
对于隐变量\(z\),对抗损失函数为: \[ \mathcal L_{adv-d_z}(x,g,D_z)=E[\log(D_z(\mathcal N(0,1)))]+E[\log(1-D_z(g(x)))] \] 对于样本\(x\),对抗损失函数为: \[ \mathcal L_{adv-d_x}(x,D_x,f)=E[\log(D_x(x))]+E[\log(1-D_x(f(\mathcal N(0,1))))] \]
Autoencoder Loss
\[ \mathcal L_\text{error}(x,g,f)=-E_z[\log(p(f(g(x))|x))] \]
Full Objective
\[ \mathcal L(x,g,D_z,D_x,f)=\mathcal L_{adv-d_z}+\mathcal L_{adv-d_x}+\lambda \mathcal L_\text{error} \]
下图为模型重构的例子:

Experiments
Datasets
- MNIST. 手册数字识别数据集。
- The Coil-100. 包含7200张100个不同物体的不同角度的图片。
- Fashion-MNIST. 手册数字识别数据集彩色版。
- Others. 前三个数据集都是采用一个类作为inlier,而其他类作为outlier。在这一设置中inlier采样自数据集CIFAR-10(CIFAR-100),而outlier采样自TinyImageNet、LSUN和iSUN。
Results
MNIST Dataset
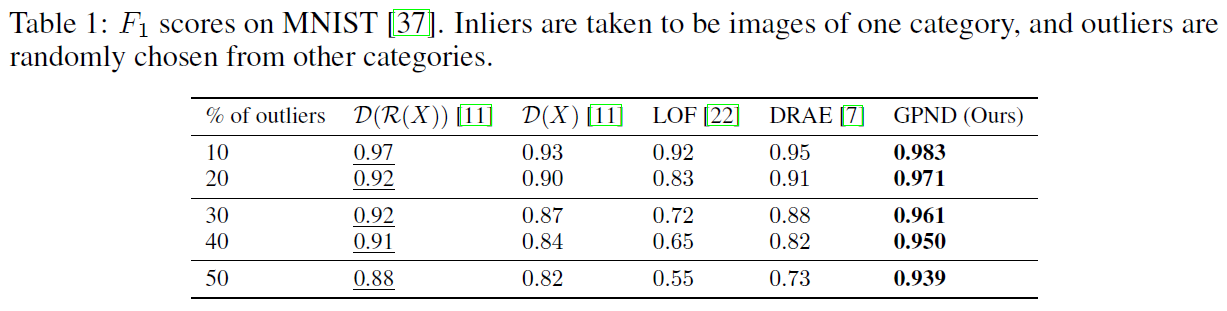
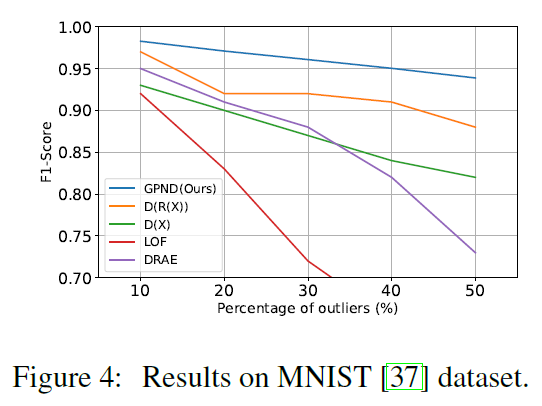
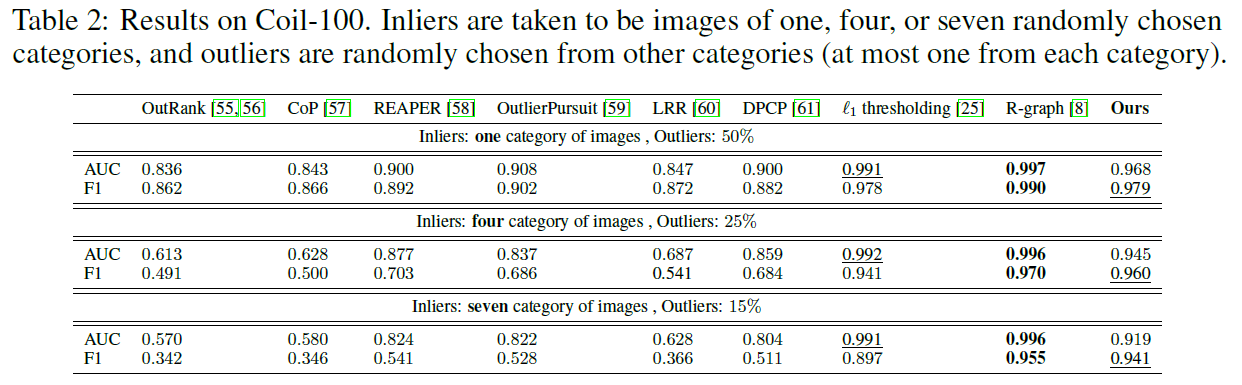
Coil-100 Dataset
Fashion-MNIST

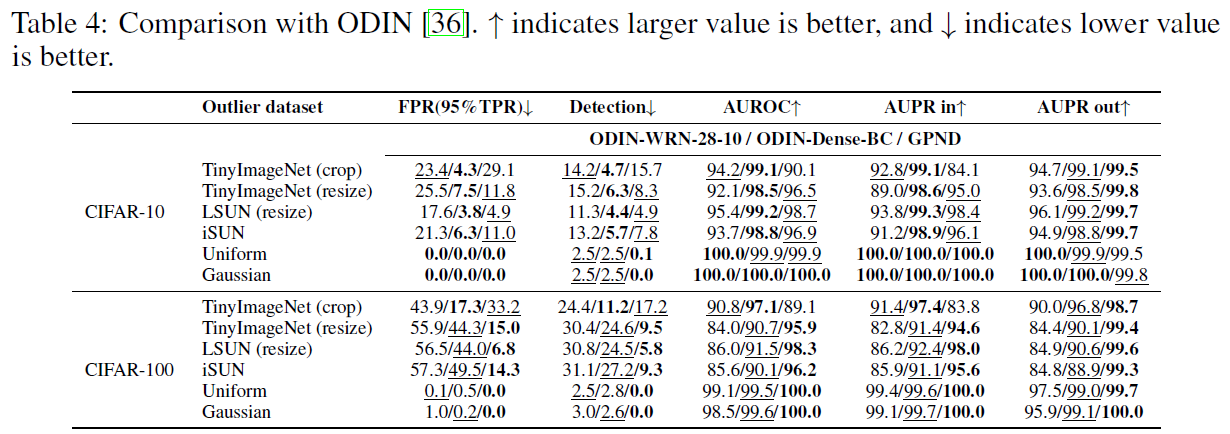
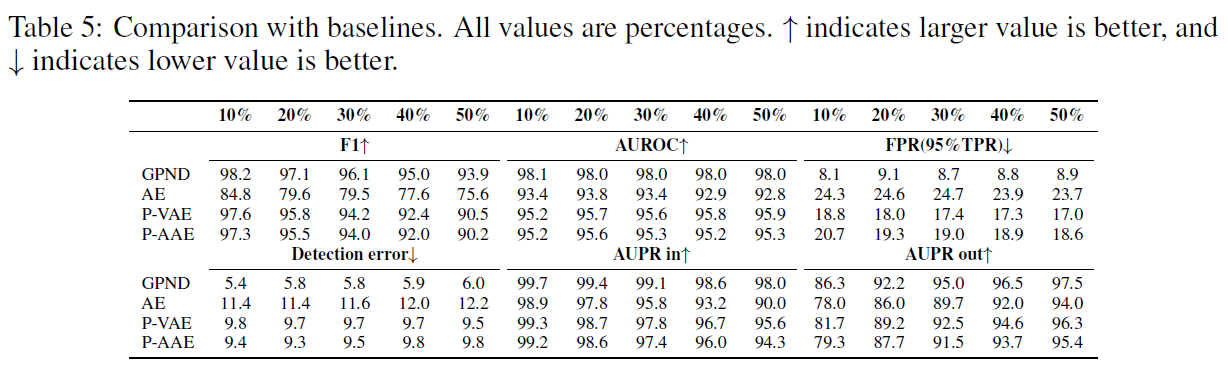
CIFAR-10 (CIFAR-100)
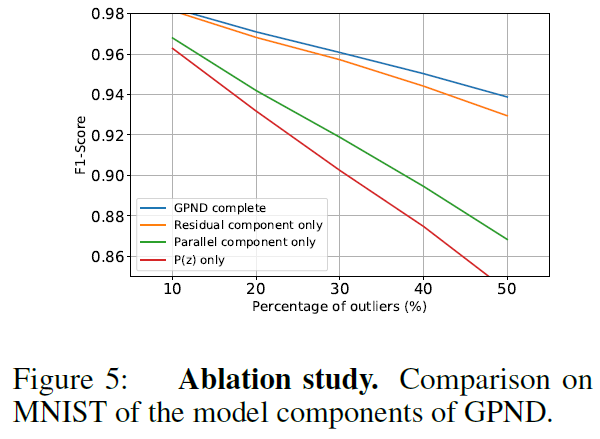
Ablation
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!