面向OpenPAI的Docker镜像配置及OpenPAI基本使用方法
本文最后更新于:2 年前
Introduction
实验室服务器集群采用OpenPAI来进行GPU资源的管理,而OpenPAI采用了Docker作为基础,即代码都放在Docker容器中运行。由于Docker的使用、Docker镜像的配置都有一定的门槛,所以这里写一篇Tutorial来进行介绍。本文不是网上资料的拼凑,而是经过本人走弯路踩坑形成的"Best practice"。主要内容包括Docker的介绍、Docker的基本使用、如何配置自己的Docker镜像以及OpenPAI平台的基本使用,但不包括Docker和OpenPAI的安装。
2020.8.1 Update: 加入通过HDFS读取容器保存的文件的方法
Docker from Scratch
要理解Docker是什么,从虚拟机开始讲可能会比较好理解。虚拟机大家可能都很熟悉了,比如说我用的系统是Windows,但我需要Linux系统来作为一个Flask编写的网站的服务器,但是又不想单独安装Linux系统,于是可以使用虚拟机来解决这个问题。安装VMWare Workstation,去官网下载Ubuntu系统镜像,然后在VMWare中安装好系统,然后从头配置Flask相关环境。实际上我需要的仅仅是一个Flask运行环境而已,而使用虚拟机却需要如此“大费周章”,这时Docker出现了,网上有大量现成的Flask Docker镜像,配置好了你所需的Flask环境,你只需要下载这些镜像,然后运行它,你就得到了一个Flask运行环境,而与你当前使用的系统无关。如果你需要一个Tomcat的运行环境,那么去找一个Tomcat的Docker镜像就行。Docker将需求或者说服务绑定在了Docker镜像中(轻量化,一个需求对应一个Docker镜像,每个镜像都很小),你有什么需求,去找相应的镜像即可(或者自己写一个),镜像的运行是以虚拟机的形式存在,所以他们之间也是互不干扰的。同时,你在写好一个Docker镜像之后,你还可以分享给别人,这样其他人就不用重新配置,直接运行你给他的镜像即可。Docker有两个比较关键的概念:
- 镜像 Images: 这里的镜像不是指我们安装系统时下载的ISO镜像,Docker镜像就是把你需要的东西(一个系统+需要的服务)集中到一起,相当于做菜的菜谱;
- 容器 Containers: 如果一个Docker镜像启动了,那么就会有一个Docker容器产生,相当于按照菜谱做出来的菜。
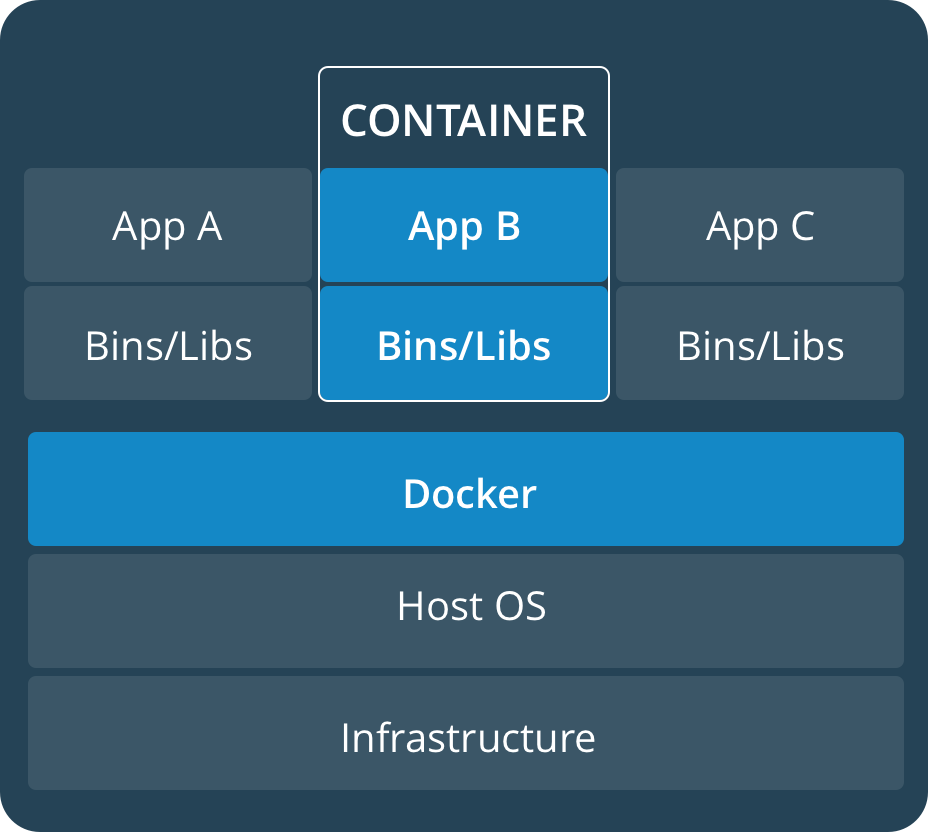
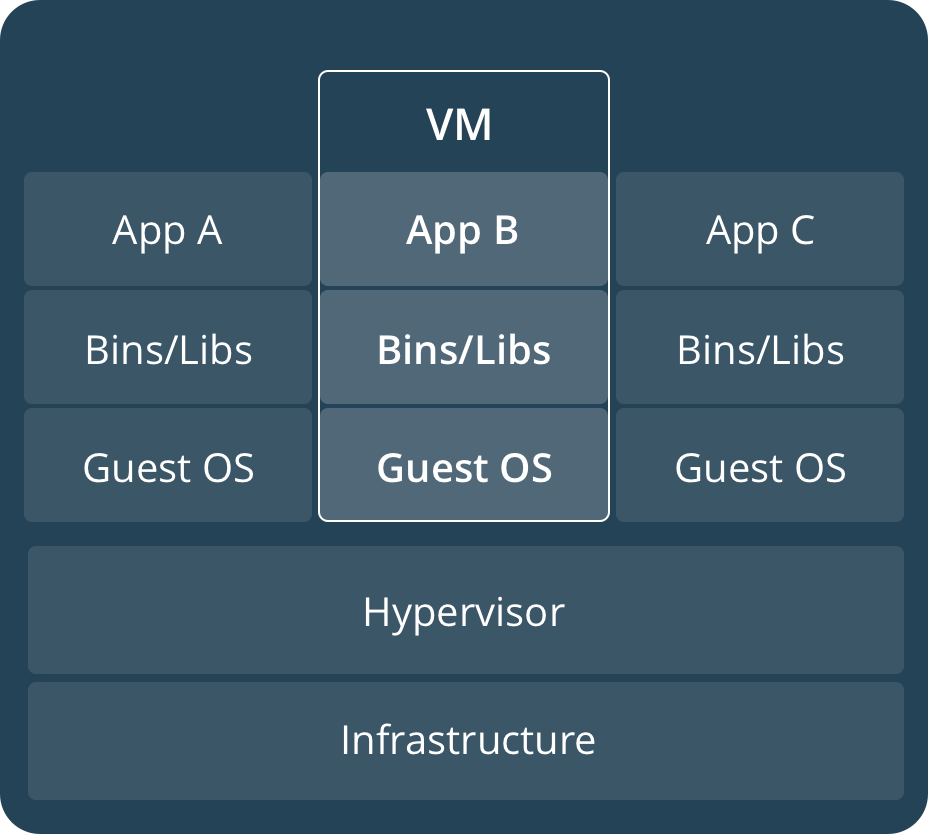
这一节我们先不讨论如何自己写Docker镜像,只是先讨论Docker的基本操作。
Basic Operations
Docker新安装好当然是没有什么镜像的,首先我们使用docker pull hello-world来下载一个测试镜像。
拉取镜像
docker pull <image_name>
在输入之后,Docker会自动在远程服务器上查找对应的镜像进行下载。由于我的电脑上已经有这个镜像了,所以显示是下面的样子:

接下来,我们输入docker run hello-world运行这个镜像。
运行镜像
docker run <image_name>
可以看到,Docker输出了一些信息就自己退出了,这和我们理解的虚拟机不太一样。在Docker里面,我们既可以创建一个完整的系统,用户在运行之后就可以正常使用这个操作系统,也可以创建一个简单的服务,默认运行完一些指令就退出了。这里的hello-world镜像这是输出了一些信息后就自动退出了,因为这就是这个镜像的全部内容。
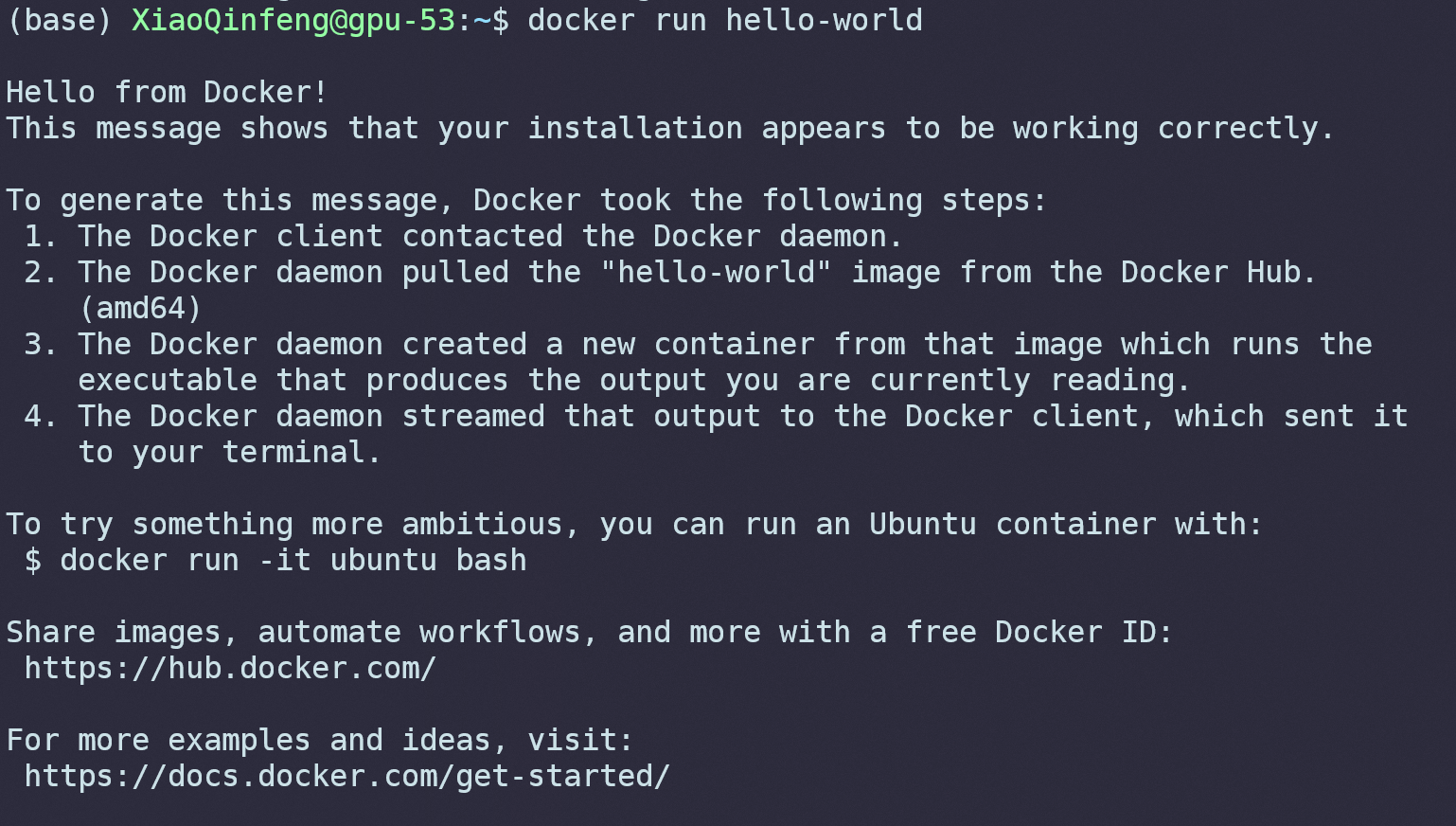
我们尝试来运行一个完整的系统,先用docker pull ubuntu拉取Ubuntu Docker镜像:
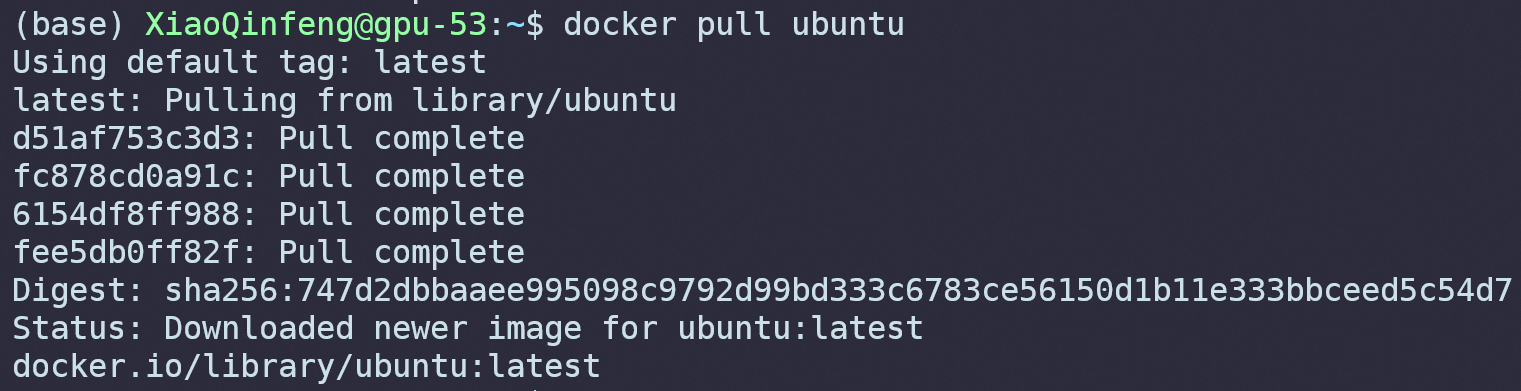
接下来我们使用:

-it的意思是什么?根据docker run --help:
2
3
4
5
6
7
8
9-i, --interactive Keep STDIN open even if not attached
--ip string IPv4 address (e.g., 172.30.100.104)
--ip6 string IPv6 address (e.g., 2001:db8::33)
--ipc string IPC mode to use
--isolation string Container isolation technology
--kernel-memory bytes Kernel memory limit
-t, --tty Allocate a pseudo-TTY
--ulimit ulimit Ulimit options (default [])
Copy其实
-it是-i和-t的合并写法,意思是运行后进入这个容器并且启用shell,不然运行之后就会放到后台而不会进入容器中。而--rm则代表容器退出之后会被删除(镜像不会被删除),每次运行实际上会创建一个新的容器,如果不加--rm或退出之后不手动删除的话会看到一堆停止运行的容器。
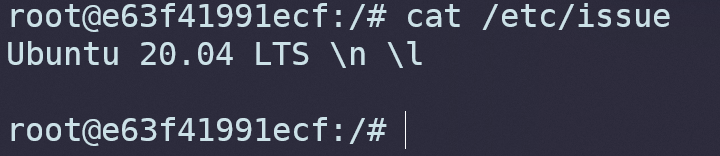
输入cat /etc/issue可以看到默认拉取的是最新的Ubuntu 20.04 LTS:
Build Customized Docker Images
如果没有现成的Docker镜像能满足我们的需求,我们可以考虑自己写一个。要自定义一个Docker镜像需要两步,第一步是编写Dockerfile,第二步是使用docker build命令构建镜像。Dockerfile可以看作是一个脚本,描述了我们构建镜像所需要的全部命令,比如要构建一个用于Python科学计算的Docker镜像,我们需要在Dockerfile中编写安装Python的命令,安装Numpy、Scipy等常用包的命令等等。我们先来上手编写Dockerfile,这里我准备写一个包含hexo博客框架的镜像,这个框架需要node作为基础环境,不过我们不需要在Dockerfile里写安装node的命令。因为类似于C++或Python中的对象的继承,Dockerfile也可以“继承”,这意味着我们不必从头写起。我们先来看一下完整的Dockfile和效果,再来一一解释。
1 | |
运行结果如下所示,可以看到Docker按照我们写的Dockerfile一行一行的进行镜像的构建:
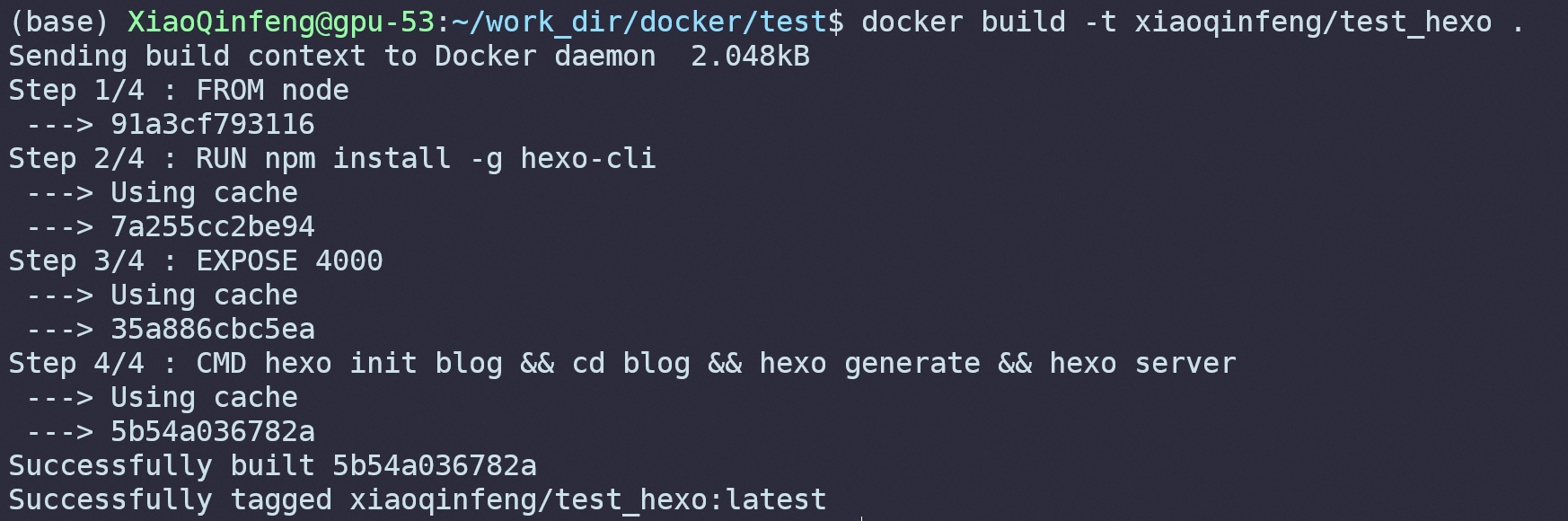
现在来解释Docerfile里的内容。FROM <docker image>表示继承其他的镜像,这里我们使用node官方的镜像。接下来是安装hexo,RUN <command>表示执行命令,这里我们直接用npm install -g hexo-cli进行安装。由于要浏览博客网页需要开放端口,而Docker容器运行的时候和外部主机是完全隔断的,要使外部主机访问Docker容器端口,需要暴露端口。EXPOSE <port>代表暴露端口,这里用的是4000端口。之后是创建博客和启动本地服务,CMD <command>和RUN <command>的区别是RUN会在构建的时候执行,而CMD是在容器启动之后才会执行。hexo init blog && cd blog && hexo generate && hexo server分别代表初始化博客、进入博客所在文件夹、生成博客网站、启动本地服务器。更多指令可以参考官方文档。
然后我们使用docker build -t test_hexo .命令构建镜像。
构建镜像
docker build -t <image_name> <direcotry>
运行镜像:
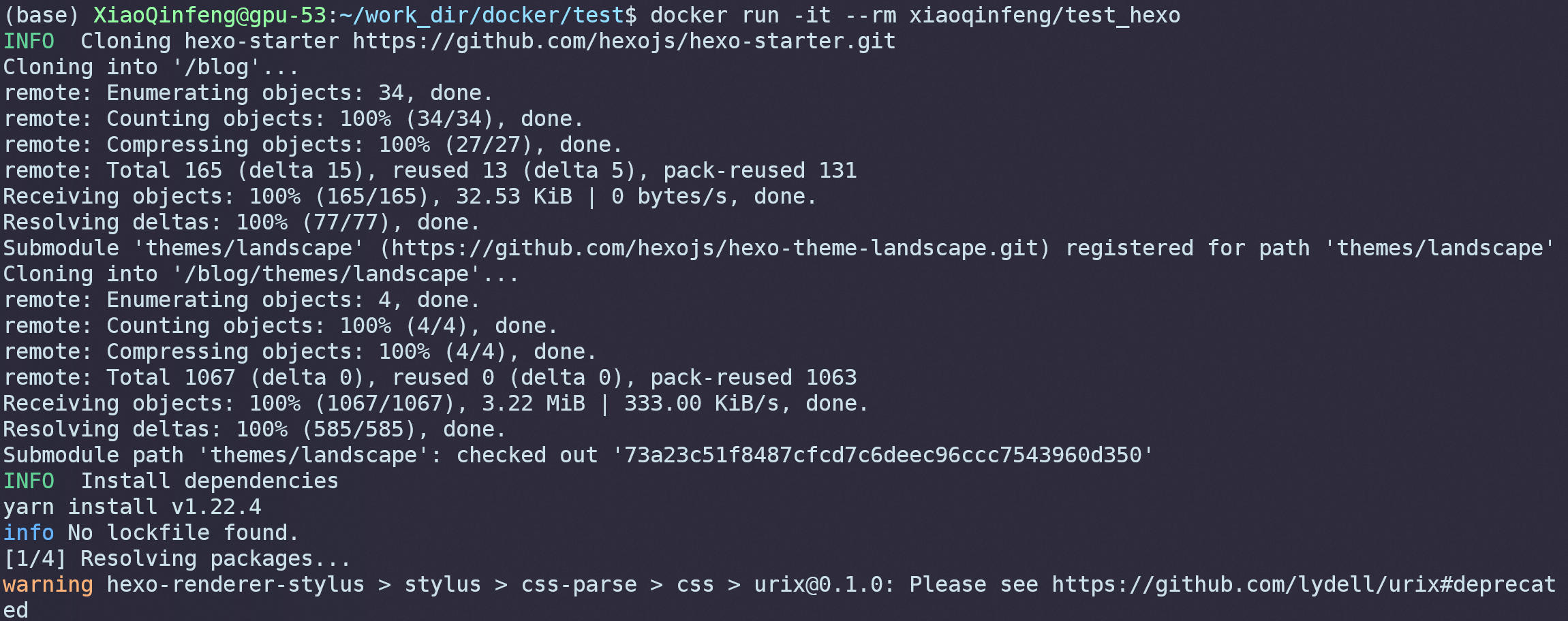
可以看到容器启动后开始执行博客初始化。
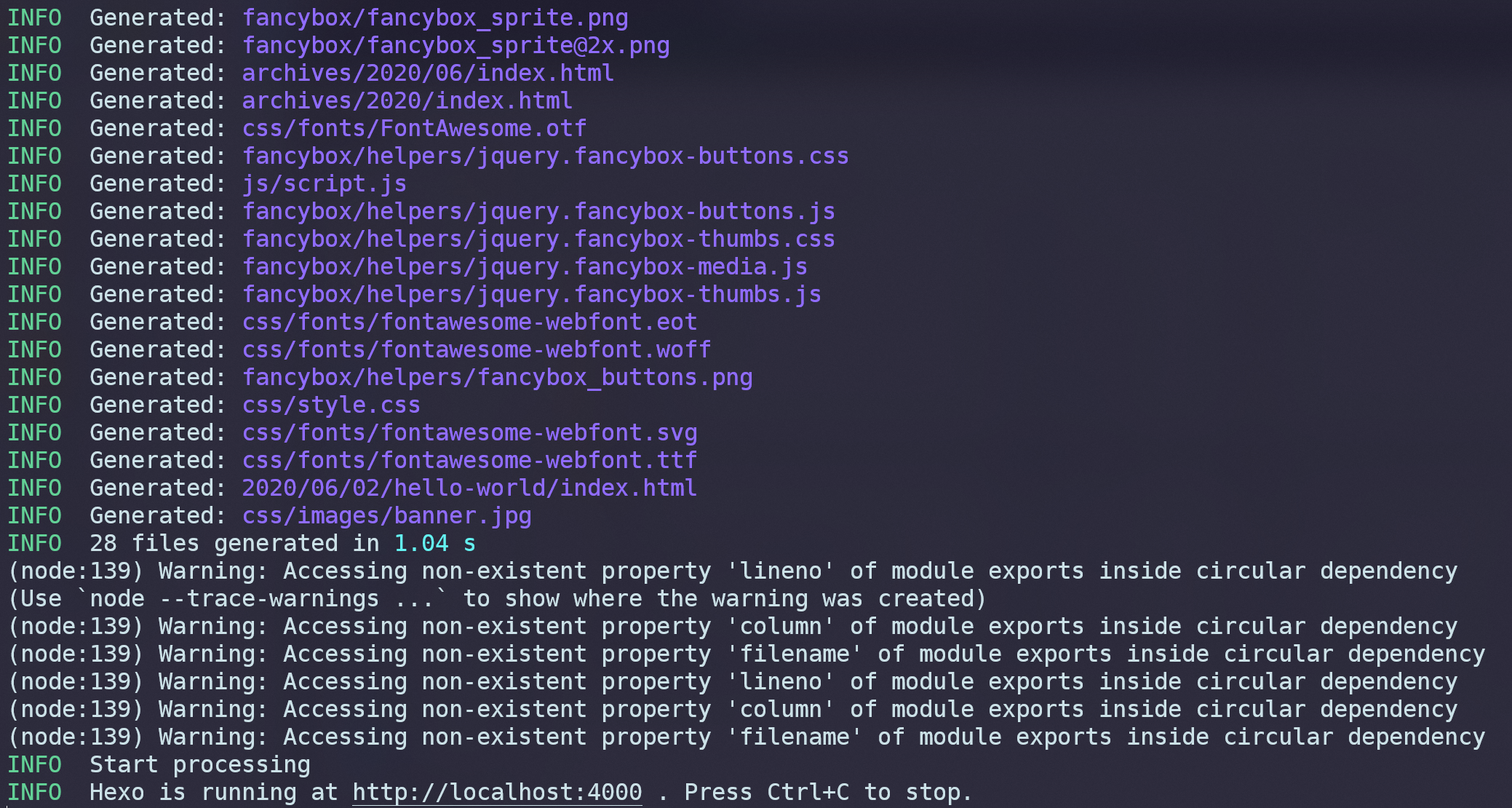
最后在locahost:4000上启动了一个本地服务器,在浏览器中输入这个地址,可以看到刚刚构建好的博客:
值得注意的是,在Dockerfile中我们暴露了4000端口,使用-p标签可以达到同样的效果:docker run -p <docker_port>:<local_port> <image_name>。比如docker run -p 9999:8888 xxxx代表将Docker容器中的9999端口转发到外部主机的8888端口。如果你是在远程服务器上使用的Docker,那么端口只是被转发到了远程服务器上,还得手动将远程服务器再转发到你本机上才能直接在本机浏览器上看到页面。
Build Docker Images with Aliyun Container Registry
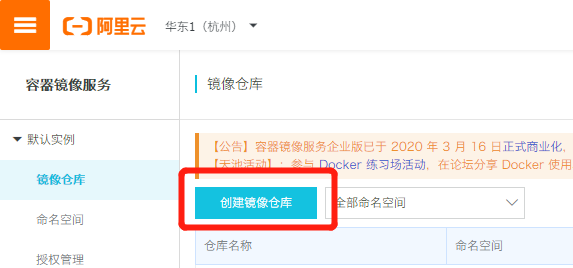
因为某些原因,如果在构建镜像的时候需要通过apt-get update更新源,会发现无论如何都会卡住。这个时候可以使用阿里云容器镜像服务,在阿里的服务器上构建好镜像,再拉取到自己的机器上。注册好帐号之后,点击创建镜像仓库:
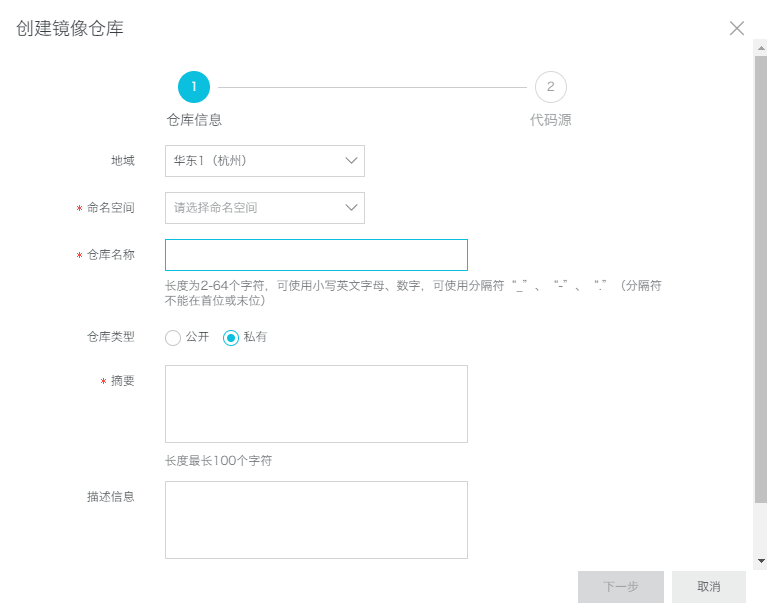
这里仓库类型如果没有特殊需求建议使用公开,然后填写一些基本信息:
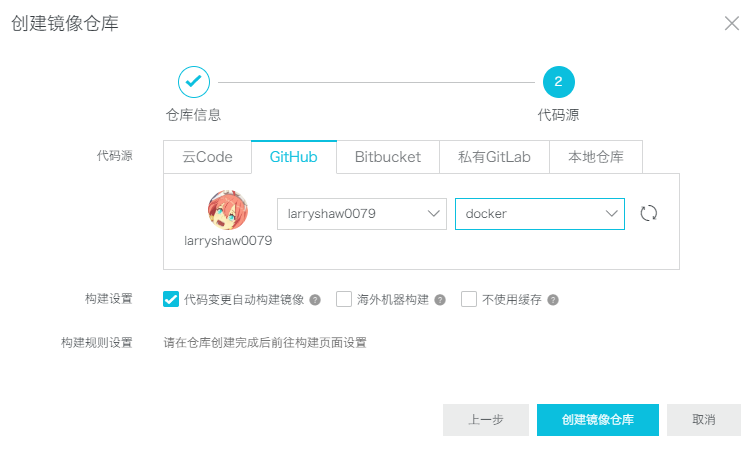
之后设置代码源,其实就是告诉阿里云从哪儿获取Dockerfile,我这里用的是Github,所以需要先在阿里云中关联Github账号,然后在Github中创建一个用来放Dockerfile的仓库。构建设置里有一个“海外机器构建”,这正是我们使用阿里云容器服务的主要目的,勾选。
镜像仓库创建好之后,点进去,在构建页面点击添加规则:

按下图进行设置即可,镜像版本就是你想要的镜像名字:
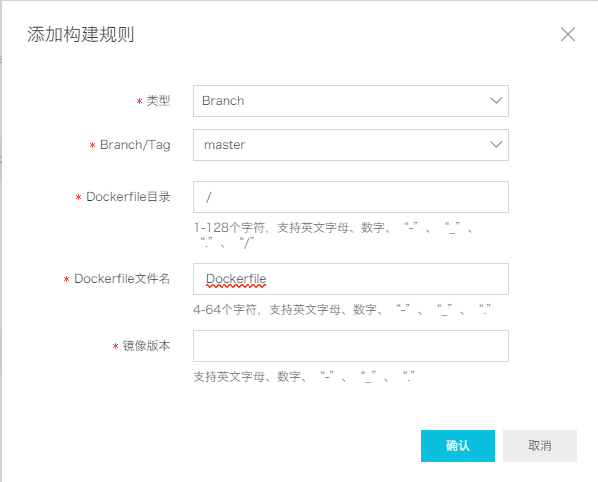
点击“立即构建”:

等待一段时间后,如果构建成功,便可以进行拉取了,在镜像仓库的基本信息页面可以看到地址:
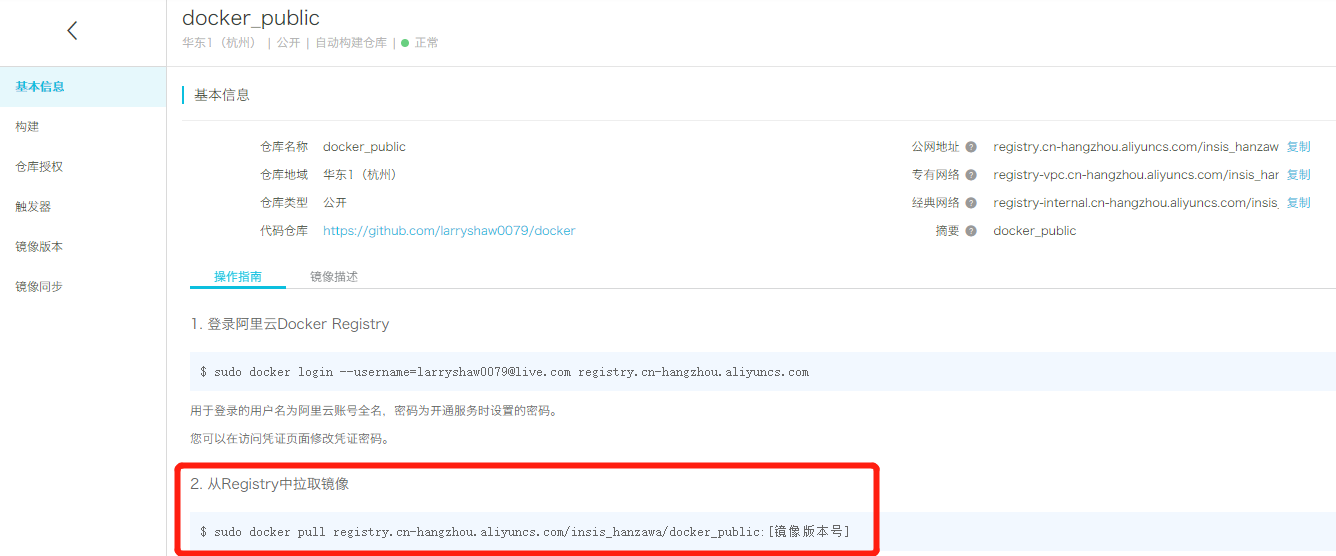
将阿里云上的镜像拉取到本机之后一般会想要对镜像改名,可以使用docker tag <old_name> <new_name>。
Build Docker Images for Deep Learning
Startup
在Docker中配置适用于OpenPAI的深度学习镜像不是一件容易的事,会有很多的坑,这里专门说一下如何配置。推荐在阿里云容器镜像服务中进行构建,会少很多麻烦。
第一步是初始镜像,由于需要用到CUDA,这里可以根据自己的需求(比如不同CUDA版本支持的GPU驱动版本不一样,还有Tensorflow不同版本对CUDA和cuDNN要求也不一样)从Nvidia的Dockerhub官方页面选择合适的CUDA和cuDNN版本:
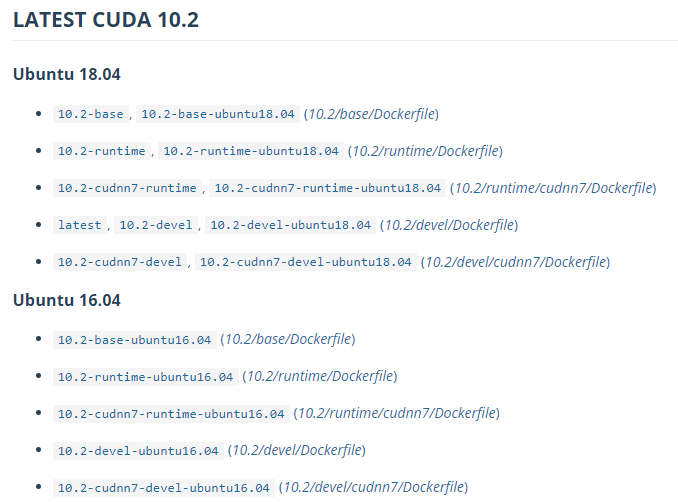
这里我们选择CUDA10.1 + cuDNN7:
1 | |
这一条主要是解决乱码问题以及定义用到的软件包的版本,这里Miniconda版本设置为4.5.4的原因是这是最后一个自带Python3.6的版本,我在这儿为了稳定所以用了Python3.6,大家也可以安装最新版的Miniconda:
1 | |
接下来安装必须的包,大家可以根据需求自行调整,-y标签代表Yes,即自动同意安装:
1 | |
安装Miniconda并设置环境变量,-b标签可以让Miniconda无交互自动安装:
1 | |
安装Hadoop,OpenPAI平台会用到:
1 | |
ENV的作用是配置环境变量。配置JAVA和Hadoop环境变量:
1 | |
设置PATH环境变量:
1 | |
完整的Dockerfile如下:
1 | |
建议先把这一部分进行构建,作为基础镜像,后面要配置其他环境(如安装Pytorch框架登),就不用重复构建这部分,还减少了出错的可能性。这里说一下,启动带CUDA的Docker镜像需要在docker run加上额外的参数--runtime nvidia。
接下来安装深度学习框架。
Configure PyTorch
假设上面的镜像我们命名为xiaoqinfeng/base,那么构建PyTorch的Dockerfile可以像下面这么写:
1 | |
因为这里我用的CUDA10.1,其他版本的CUDA安装指令可能不太一样,具体可以参考官网。
Configure Tensorflow
如果是安装Tensorflow,那么构建Tensorflow的Dockerfile可以像下面这么写:
1 | |
这里会自动安装最新版本的Tensorflow2。Tensorflow不同版本对CUDA和cuDNN版本甚至Python版本的支持都不太一样,可以参考官网的说明。
Deep Learning with OpenPAI
What is OpenPAI
OpenPAI是一个分布式深度学习计算资源管理平台,对于我们用户来说,只需要定义好Docker镜像,然后编写好任务设置,提交到平台之后,平台便会自动分配计算资源来运行任务。
OpenPAI界面:
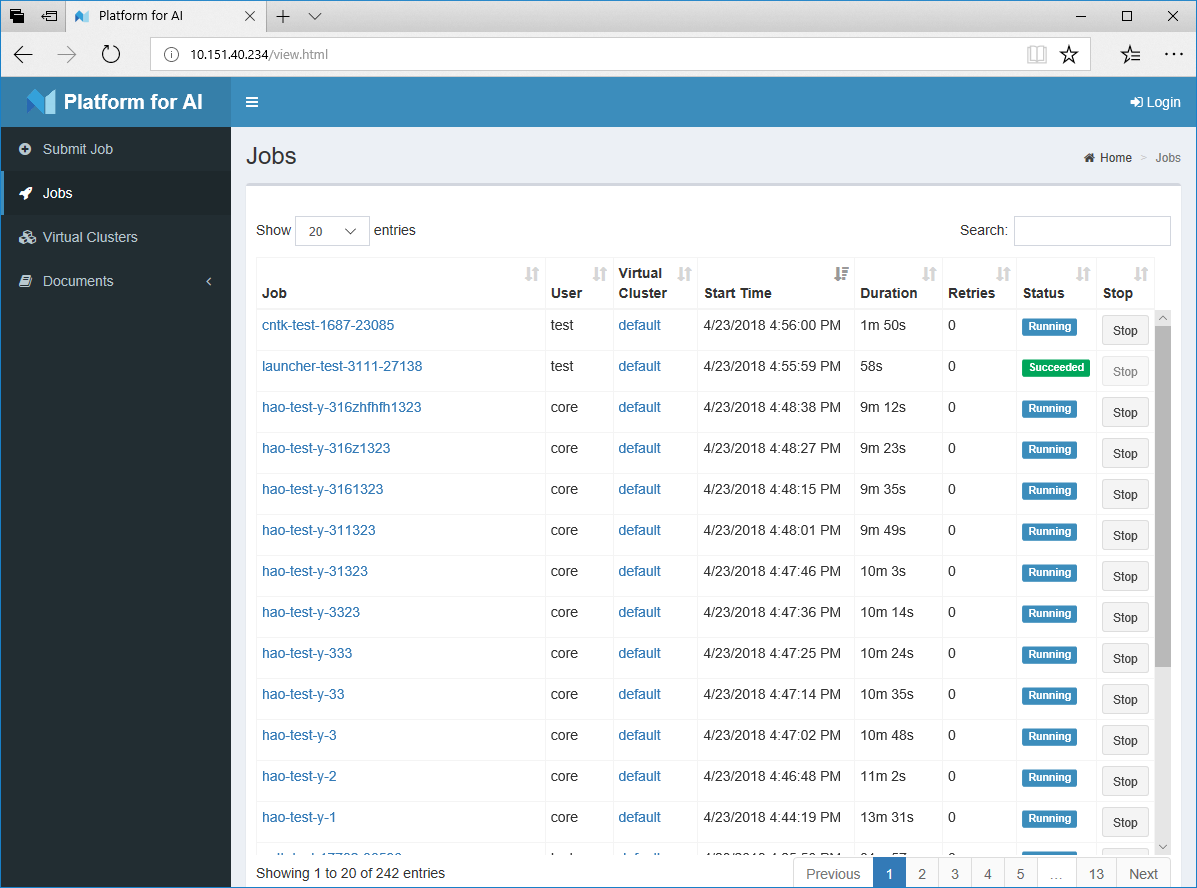
下面我们来讲讲怎么向OpenPAI平台提交任务。
Submit Jobs to OpenPAI
Pack Code & Data Files
假设你已经完成了代码的编写和测试,你的目录结构可能看起来是这样:
1 | |
因为OpenPAI会创建一个虚拟容器来运行你的代码,所以你的数据和代码必须要以某种方式传送到OpenPAI上的虚拟容器中。我们先来打包,在代码目录下执行tar -cvf files.tar ./。之后,运行python -m http.server <port>。打开浏览器输入<server_ip>:<port>应该就能看到你的文件了:
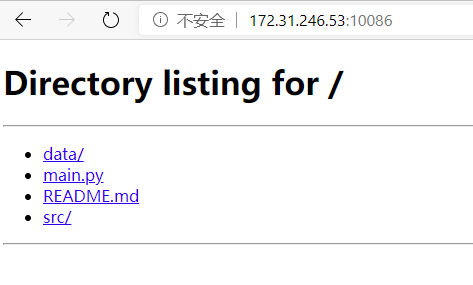
由于这个http进程需要一直运行,所以建议使用screen放到后台执行。
Configure Tasks
像OpenPAI提交任务可以采用网页提交也可以使用VSCode插件,这里我们采用网页提交。登入OpenPAI界面,点击Submit Job:
可以看到提交任务的界面:
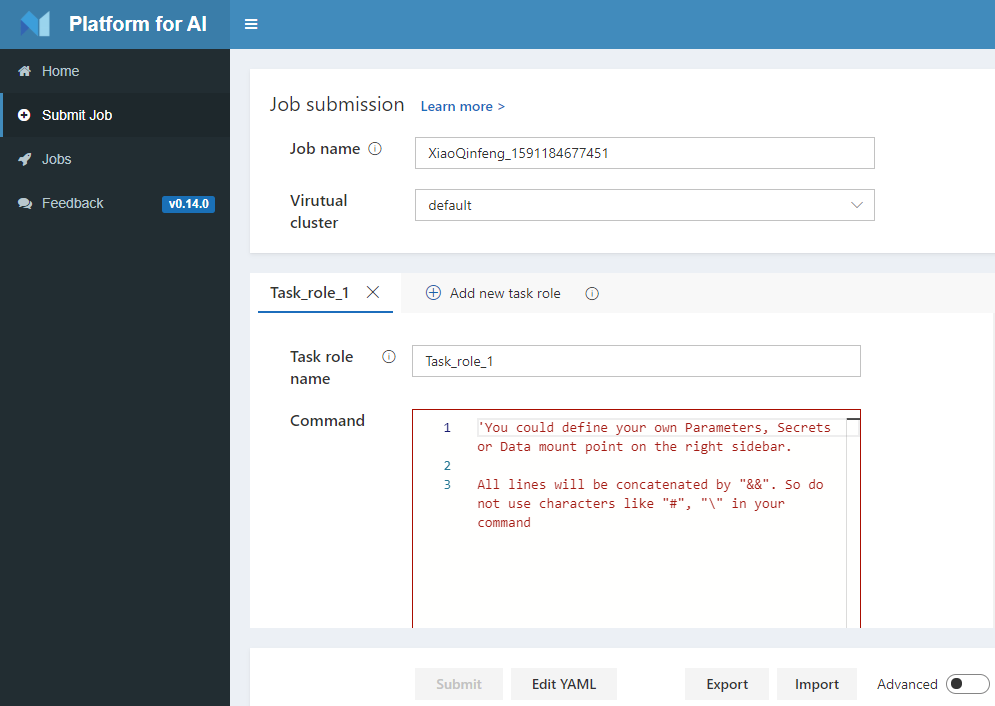
Job name大家可以自己设置。在Command一栏,是执行任务所需的全部命令,首先我们要做的就是将代码数据压缩包下载到容器中并解压:
1 | |
然后是运行代码,假设我这里的任务比较简单,只有一行main.py的调用:
1 | |
如果任务的执行比较复杂,也只需把命令填到Command里即可,OpenPAI会自动执行。接下来是设置配置,可以选GPU的数量,内存大小等等:
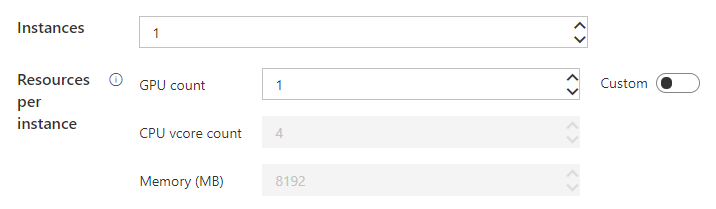
然后是镜像的选择:
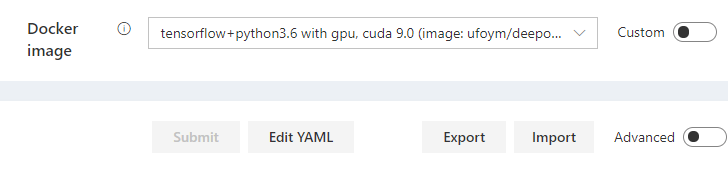
要注意在本机上构建好镜像之后,需要把镜像重命名为<repository_address>/<image_name>的格式(我们的<repository>是lin-ai-27:5000,假设我的镜像名是xiaoqinfeng/pytorch,那就是改成lin-ai-27:5000/xiaoqinfeng/pytorch),然后执行docker push推送到Docker镜像服务器上才能在OpenPAI上使用。
提交之后,可以在Jobs界面看到任务的运行情况:
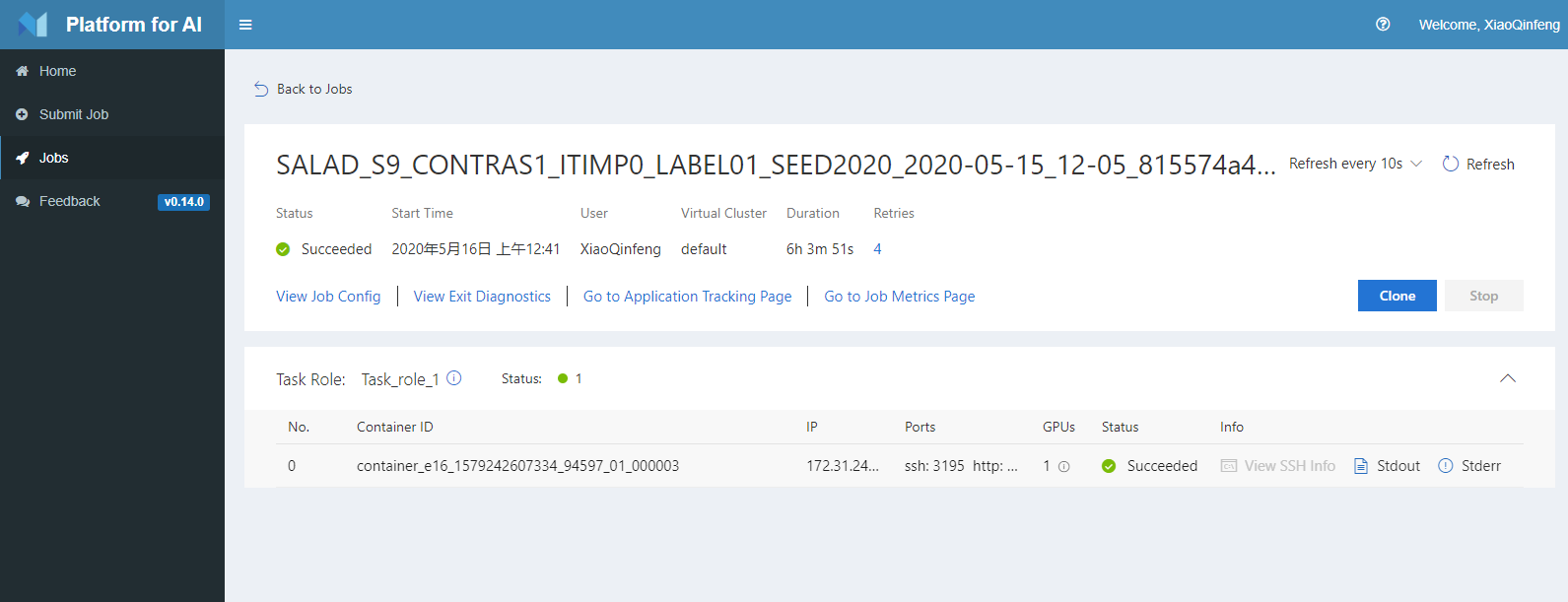
Misc
Store Files in Containers
我们往往需要在程序运行的时候保存文件,如checkpoints等。在OpenPAI上执行程序的话文件是保存在程序中的,如果我们想要在运行完之后把文件复制到本地电脑上呢?这个时候就需要在任务的配置文件里加上复制文件到HDFS的语句。首先确认你的HDFS的URL:如hdfs://172.31.246.52:9000/你的OpenPAI用户名/。
如果要创建文件夹,则可以使用hdfs dfs -mkdir -p <HDFS URL>+<New Folder>。这里<New Folder>是你要创建的的文件夹的路径,用起来和Linux的mkdir命令其实是差不多的。
要复制文件(夹)则使用hdfs dfs -cp <Source Dir> <Dest Dir>。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!