Cross-dataset Time Series Anomaly Detection for Cloud Systems
本文最后更新于:2 年前
Introduction
本文介绍了一种用于云计算平台的时间序列异常检测框架。为了解决标签不足的问题,文中使用了迁移学习的方法,即在有标签的source domain上训练模型,在没有标签的target domain上检测。同时,文中还使用了主动学习的方法来挑选最有价值的无标签样本进行标记。
Background
针对云计算平台数据的异常检测通常是应用在云监控数据,如KPI、CPU使用率、系统负载等时序数据上。和传统的异常检测不一样的是,时序异常检测往往更难,文中总结了以下几个挑战:
- 异常特征的差异性。在不同的云服务系统中,对异常的容忍度是不同的,所以对每个场景或系统组件设置准确的阈值来进行异常检测是十分困难的;
- 时间依赖性。该异常检测问题处理的是时间序列数据,而传统的异常检测并不会考虑时间依赖性;
- 无监督学习的性能问题。无监督的异常检测方法的性能有限,会带来大量的误报;
- 有监督学习需要大量标签。
Proposed Approach
为了解决上述挑战,文中提出了一个时间序列异常检测框架ATAD (Active Transfer Anomaly Detection)。该框架结合了迁移学习技术和主动学习技术,示意图如下:
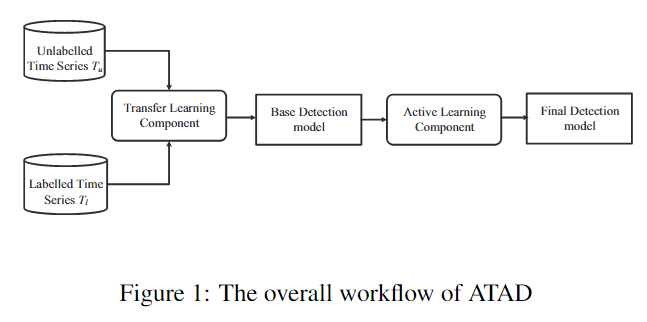
未标记数据\(T_u\)是我们要检测的目标数据 (target domain),标记数据\(T_l\)是我们的源数据 (source domain),可以是开源数据或者是其他系统的监控数据。
Transfer Learning Component
在应用迁移学习时,我们需要考虑以下几个因素:
- 我们处理的是时间序列数据,即在不同的时间点上样本之间不是相互独立的。为了解决这个问题,我们提取了不同的特征,每一个时间点被转换为了高维的特征向量,且每个时间点附近的背景信息被保存在了特征向量之中;
- 时间序列的粒度。粗粒度的迁移学习不利于发现异常,本文采用细粒度,即数据点级别的迁移学习;
- 迁移学习需要source domain和target domain具有潜在的相似性,所以我们需要对source domain中的样本进行过滤。
Feature Identification
这一节描述特征工程中用到的特征。在提取特征之前,文中使用了离散傅里叶变换来识别时间序列的周期\(p\),并为后面滑动窗口的大小原则作参考。
Statistical Features
统计特征包含了一些基本的统计信息,如均值、方差等,用到的特征如下表所示:
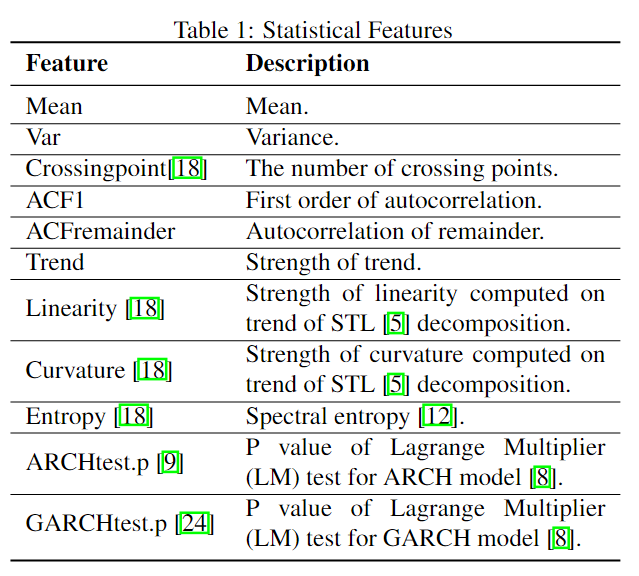
表中的统计特征都是基于大小等于周期\(p\)的滑动窗口的。
Forecasting Error Features
使用预测特征的理由是如果一个数据点偏离预测值很远,那么它很有可能是异常。文中使用了多种时间序列预测模型,如SARIMA、Holt、Holt-Winters、STL等。最终的预测结果使用下式来加权集成: \[ \hat{Y}_t=\sum\limits_{m=1}^{M}\frac{\hat{Y}_{m,t}}{M-1}\left(1-\frac{RMSE_{m,t}}{\sum\limits_{n=1}^M RMSE_{n,t}}\right) \] \(M\)代表\(M\)个不同模型,\(RMSE_{m,t}\)代表模型\(m\)在时间\(t\)的\(RMSE\),\(\hat{Y}_t\)是在时间\(t\)的最终预测结果。之后,使用下表中的Metrics来计算不同预测特征:
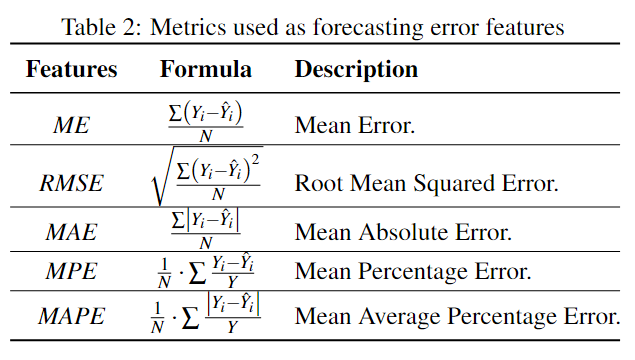
同样的,上述特征都是基于窗口的。
Temporal Features
这一部分是一些时间序列相关特征:
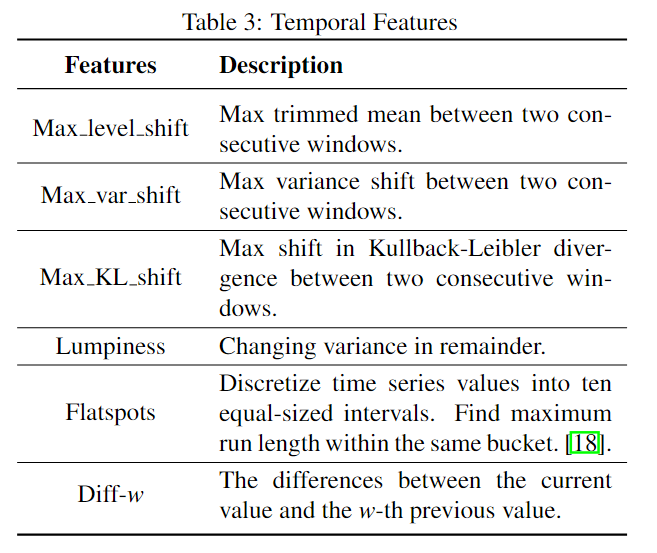
最后,总共提取了37个特征,并且每个特征都进行了正则化。
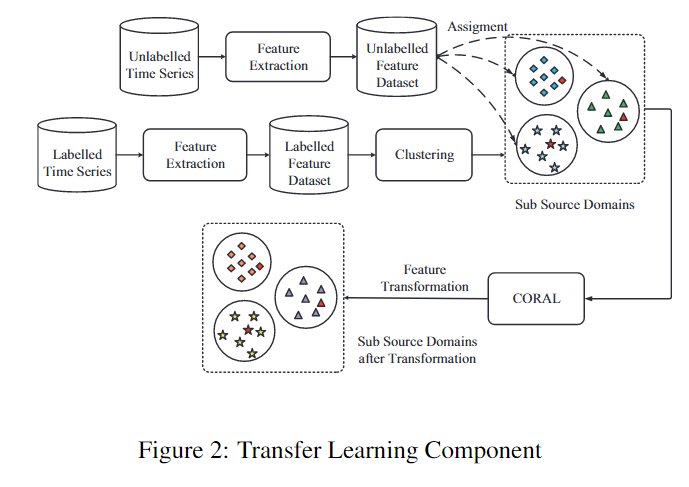
The Transfer between Source Domain and Target Domain
本文结合了基于实例的迁移学习(Instance-based Transfer Learning)和基于特征的迁移学习(Feature-based Transfer Learning)。
首先,source domain中的数据差异性是比较大的,所以我们需要选择与target domain相似的样本。
基于实例的迁移学习(Instance-based Transfer Learning)的思想是选择source domain中与target domain相似的样本。对于source domain,在将时间序列\(T_l\)转换为特征\(F_l\)之后,本文使用\(K-means\)算法将\(F_l\)分成若干个簇。每个簇\(F_l^i, i\in[1,K]\)是\(F_l\)的不重叠子集。为了选择合适的样本,我们计算了target domain中的样本和每个簇中心点的欧几里得距离,然后样本会和距离最近的簇\(F_l^i\)联系起来。
之后,为了使source domain和target domain在特征空间的差别更小,作者在每个簇上使用了CORrelation ALignment (CORAL) 算法。CORAL是一种领域适应算法 (Domain Adaption),其基本思想是对source domain和target domain进行线性变换使其二阶统计信息(即协方差矩阵)的差别最小化: \[ \min_A\parallel A^\top C^i_lA-C^i_u\parallel_F^2 \]
在最后一步,作者在每一个sub source domain \(\hat{F}_l^i\)训练了有监督模型(随机森林或SVM),所以最后我们得到了\(K\)个基模型。
Active Learning Component
由于数据的差异性和复杂性太大,仅仅使用迁移学习的技术不足以达到很好的效果。在ATAD中,作者使用了主动学习技术来用较少的成本标注最有价值的样本来提升性能。本文中使用基于Uncertainty和Context Diversity的主动学习。
Uncertainty
大多数主动学习算法使用不确定性 (Uncertainty) 来作为选择要标记的样本的准则。 \[ Uncertainty=-|Prob(Normal)-Prob(Anomaly)| \] 其中的\(Prob\)由基模型给出。
Context Diversity
多样性 (Diversity) 也是一个选择要标记样本的重要参考。如果有两个相似的样本,那么就没有必要将他们都标记。
时间上相邻的样本往往也是相似的。
具体的来说,我们对所有样本按照Uncertainty排序,然后进行一次扫描,如果当前样本在候选集中某个样本的Context之中,我们则忽略当前样本,因为这代表当前样本和候选集中的那个样本是相似的。如果不在Context之中,我们则将该样本加入候选集中。
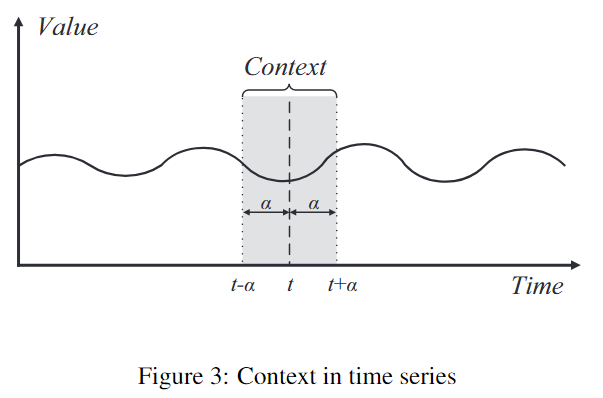
判断是否在某个样本的Context中,如下图所示,直接判断是否落在区间\([t-\alpha,t+\alpha]\)中就是了。
主动学习模块的算法流程图如下图所示:

Experiments
在实验部分,作者试图回答以下问题:
- ATAD的效果如何?
- 迁移学习模块的有效性如何?
- 主动学习模块的有效性如何?
- ATAD在基于公开数据时对公司内部数据检测效果如何?
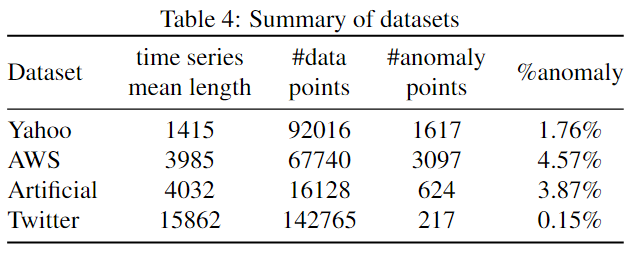
Dataset and Setup
下表是用到的数据集的一些基本信息:
Evaluation Metric
评测标准使用的是F1-score: \[ F1=\frac{2\cdot P\cdot R}{P+R}, \space P=\frac{TP}{TP+FP}, \space R=\frac{TP}{TP+FN} \]
Results
RQ1: How effective is ATAD?
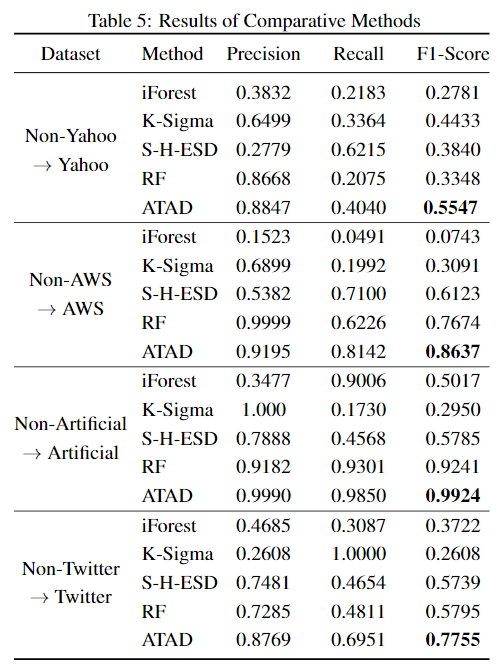
Baseline包括孤立森林、K-Sigma、S-H-ESD和随机森林。
最终结果如下表所示:
为了评测ATAD利用标签的能力,我们比较了RF在达到和ATAD相似F1 score情况下所需标签的数量,如下表所示:
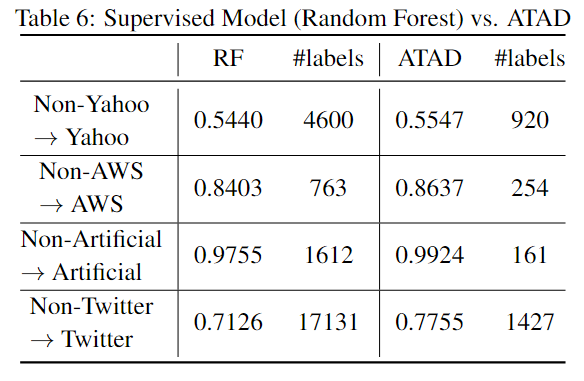
RQ2: How effective is the Transfer Learning Component?
我们从以下两个方面来探究模型迁移知识的能力:
- 使用文中所用到的特征的重要性
- 本模型迁移知识的能力
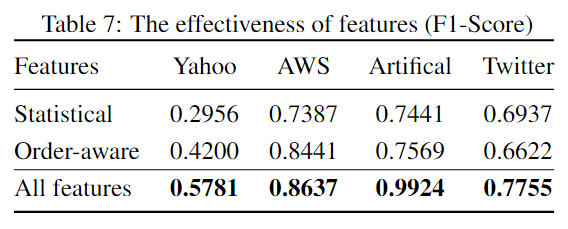
对于第一点,作者提出传统的方法一般只提取了统计特征,而本文还提取了多种其他特征。作者对提取不同特征进行了比较试验,结果如下表所示:
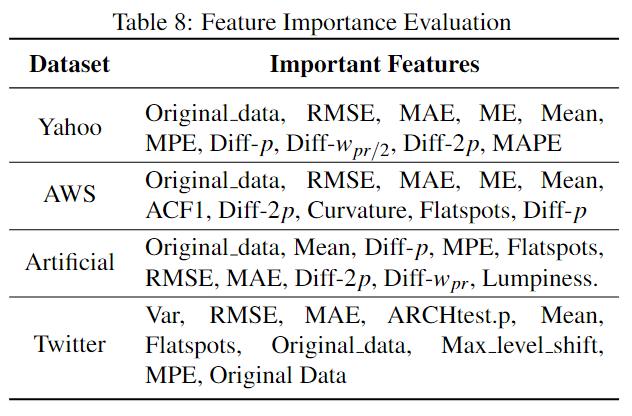
除此之外,作者还展示了不同数据集下前10有效的特征:
对于第二点,作者比较了是否使用文中的领域适应算法CORAL,在达到相似F1 score下所需的标签数,如下表所示:
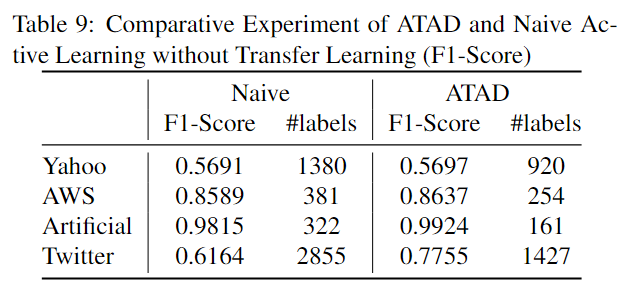
RQ3: How effective is the Active Learning component?
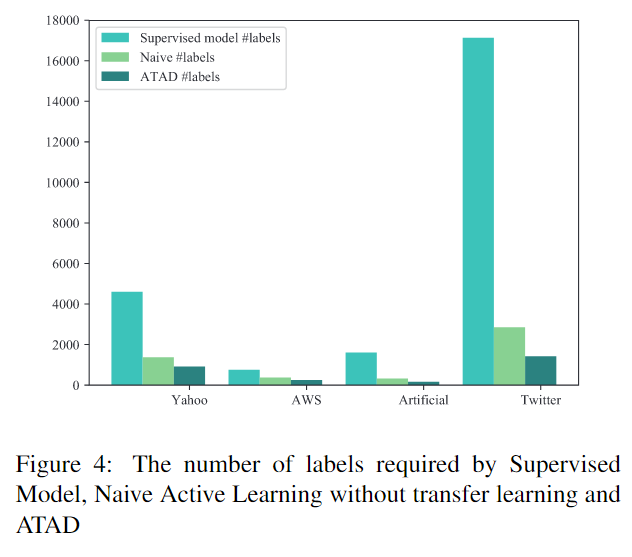
为了验证本文所用的主动学习的有效性,作者进行了对比试验。第一个模型 (Supervised model) 使用全部标签但不使用迁移学习训练,第二个 (Naïve) 为只使用主动学习而不使用迁移学习,第三个为本文提出的模型。结果如下图所示,为了达到相似的性能,不同模型需要的标签数。
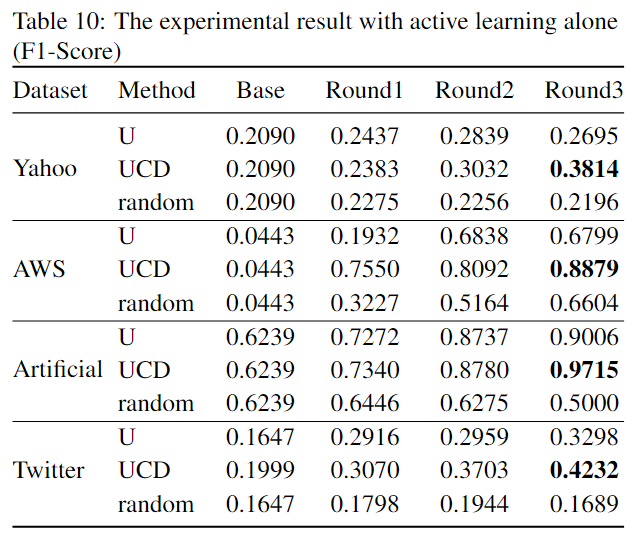
下表展示了使用不同主动学习策略 (U - conventional uncertainty method, UCD - 本文使用的方法, random - 随机选择) 进行标记得到的结果:
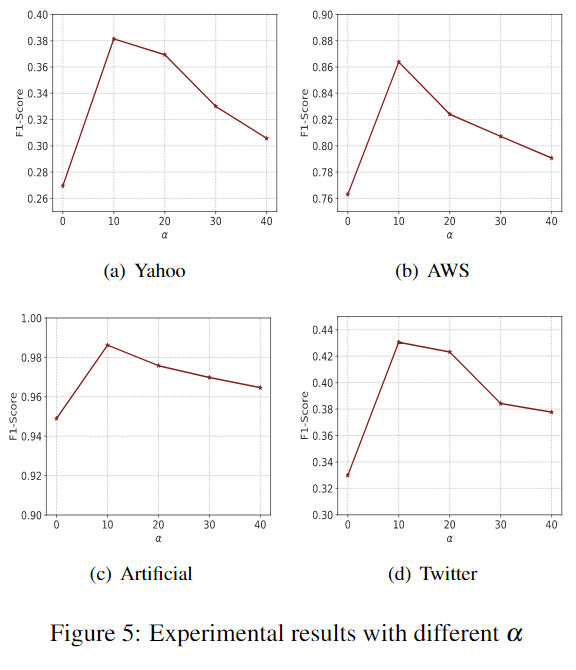
同时作者还对不同\(\alpha\)的选择进行了实验:
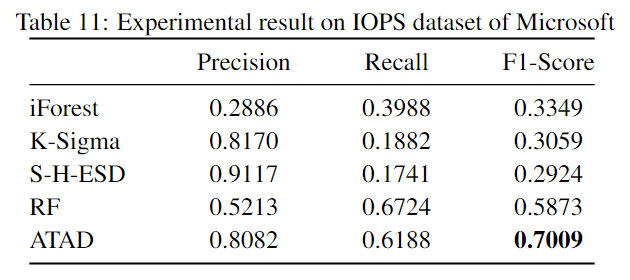
RQ4: How effective is ATAD in detecting anomalies in a company’s local dataset based on public datasets?
这里作者对比了不同方法在微软内部数据集上的结果:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!